Redis best practice
Redis에 대해 예전 회사에서 팀내 발표를 할 때 작성한 자료.
주위에서 Redis를 잘못 사용해서 문제가 생겼던 경우를 몇 번 보았다. Best practice를 알고 시작하는게 참 중요하다.
Redis Best Practice
레디스는 뭔가요?
- Redis = REmote DIctionary Server
- in-memory but persistent on disk database
- key-value DB인데 개발자에게 친숙한 데이터 타입을 제공
- mostly single threaded
Why 레디스?
- 사용하기 쉬움
- 강력한 성능
- 실제로 많은 회사/스택에서 쓰임
- 다양한 용도로 쓸수 있음 (Cache, main DB, buffer, queue)
Spec:
- $2^{32}$ 개의 key 저장 가능
- 각 hash, list, set 그리고 sorted set은 $2^{32}$ 개의 아이템을 가지고 있을 수 있음
결론부터 시작:
- KEYS 명령어는 가급적 사용하지 말자
- SAVE, FLUSH라는 말이 들어가면 피하자
- 가능하다면 TTL 꼭 설정
- 가급적 hash 데이터 타입 사용
- Redis는 single-threaded임
- Redis는 async하지 않음
헷갈리는 부분들… Single Threaded? / async? / eventloop?
- Redis에서 even loop를 사용함. 용도: client connection / IO event (ex. socket에 read/write 할 때)
- Redis Commands는:
- async하지 않음.
- atomic 함.
- 순서대로(Sequential하게) 실행 됨.
- blocking 함. 실행되기 시작하면, 끝날때까지 다른 command가 실행이 안 됨
- 여러개의 command를 마치 하나의 atomic command처럼 사용하려면 transaction/lock을 사용해야 함. 아니면 race-condition 발생가능.
메모리가 부족하면 어떻게 되나요?
메모리가 부족하면,
- Linux 커널 OOM killer가 Redis를 죽이거나
- Redis가 crash하거나,
- 서버가 swapping을 하기 시작하면서 Redis가 극심한 성능저하를 겪음
따라서, Redis의 maxmemory와 eviction policy를 같이 설정이 중요함
메모리 사용량을 줄이려면?
- 꼭 필요하다면, Redis 32 bit instance 사용…
- Redis에서 제공하는 데이터 타입 활용 (hash, list, set, sorted set)
- 위 데이터 타입의 경우 그리고 element수가 적을 경우 Redis 내부에서 특별한 구조로 저장하여 공간 절약.
- key name은 짧게…
Key name은 어떻게 지어야 하나요?
- empty string key 생성이 가능함… key 생성시, empty string이 아닌 것을 꼭 확인.
- 엄청 긴 이름은 피하자
- 최대 key size: 512 MB.
- ‘:’와 같은 구분자를 사용. 가독성도 고려.
- u1000flw
- user:1000:followers
하지 말아야 할 것 / 해야 할 것:
- O(N) operation는 조심히 사용
- KEYS *
- Redis는 single-threaded인지라, KEYS * 명령을 내리면 블로킹이 발생함. 가급적 KEYS 명령어 자체를 사용하지 않는게
- Debug용도, 또는 key가 몇 개 없을 때만 사용.
- KEYS *
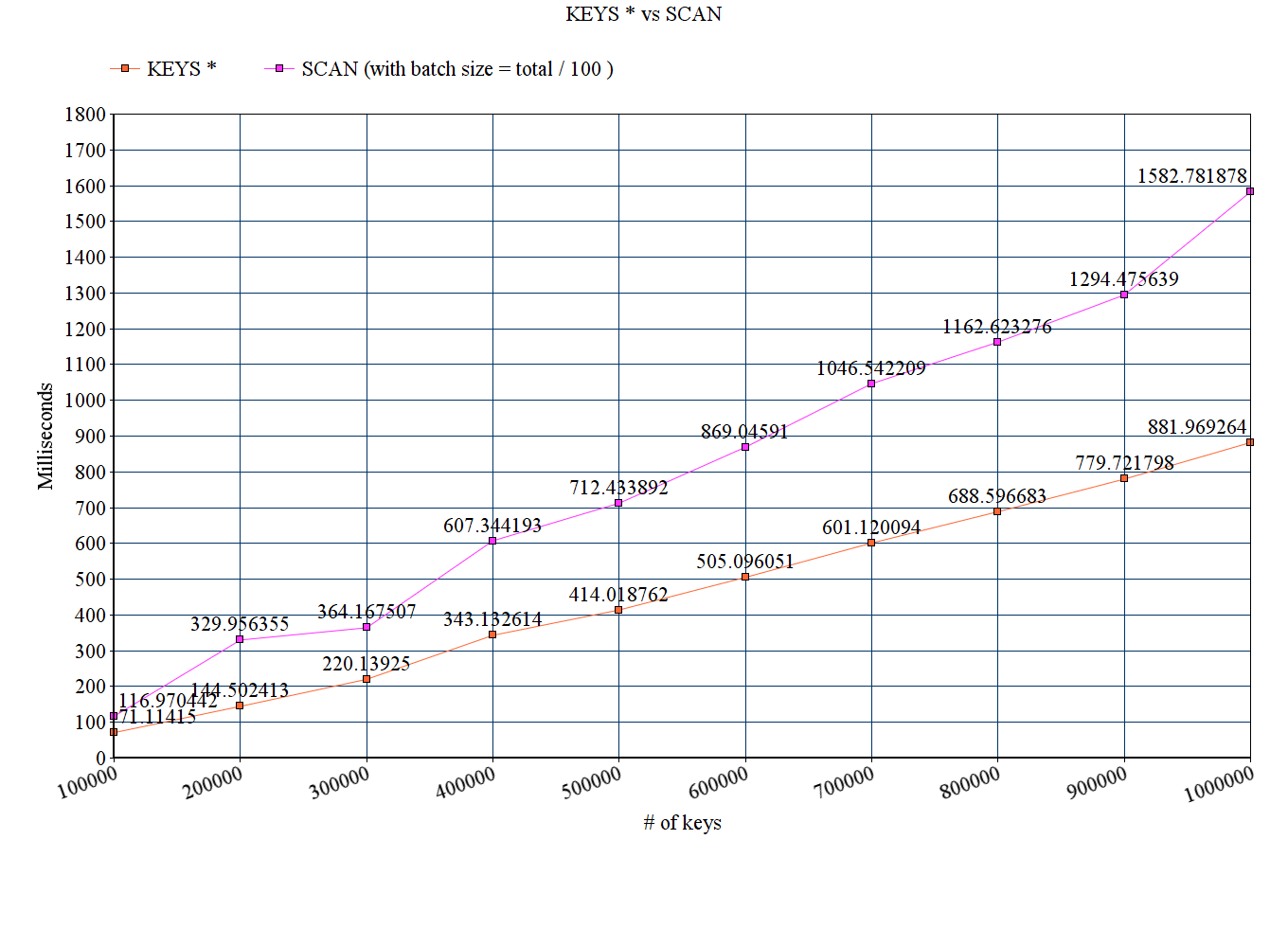
- 대신, SCAN, 또는 가능하다면 SSCAN, HSCAN, ZSCAN 을 사용
Expiration
- 가능하다면 TTL 사용
- set 보다는 list를 사용
- 메모리 사용이 적고, insert가 더 빠름
- Sorted set는 유용하나 비쌈….
Hash 사용 권장
> SET user:123:follower 5
> SET user:123:likes 20
> SET user:123:comments 30
> KEYS * // !!!! KEYS * only for debugging!
1) "user:123:likes"
2) "user:123:comments"
3) "user:123:follower"
4) "user:123"
> HSET user:123 follower 5
> HSET user:123 likes 20
> HSET user:123 comments 30
> HKEYS user:123
1) "follower"
2) "likes"
3) "comments"
- TTL 설정이 안 되고, key 자체에만 TTL 설정이 가능하다는 단점이 있음
컨넥션 재사용
- (max connection default는 10K…)
- 컨넥션 생성은 비싸고 latency를 늘림
- Redis는 ‘많은’ ‘작은 값’에 최적화 되어 있음.
- ‘Key 10개 X 100MB 데이터’ 보다 ‘Key 1K 개 X 100KB’ 를 선호
- communication buffer에 serialize를 거치고 서버의 network interface를 통과해야 하는데, 데이터 크기가 크면 성능이 떨어짐
- Redis 설정 시, Eviction policy를 사용
- maxmemory 설정만으로는 충분하지 않음
- 기본값: volatile-lru
- TTL이 걸린 key들 중, LRU가 eviction 대상
- evict할 키가 없으면, noeviction과 똑같음
- 만약 아무 key나 eviction 대상이 되도 괜찮다면, allkeys-lru 정책을 사용
- Redis 설정 시, vm.overcommit_memory 설정을 잊지 말자!
- TL;DR
- overcommit_memory = 1로 설정
- 위와 같이 설정하지 않으면, SAVE시 메모리가 조금이라도 부족하면 Redis가 죽음
- 위 설정에도 불구하고, SAVE시 메모리가 현저히 부족하면 Redis가 죽을 수 있음.
- 안정된 Redis 운영을 위해서는 Free 메모리가 충분히 있어야 함
- overcommit_memory = 1로 설정
- TL;DR
- 자세한 설명:
- Redis가 background에서 저장 명령을 실행 할 때, copy-on-write fork를 사용함.
- Redis에서 fork를 하면서 child process를 생성하고 그 child process가 DB를 덤프함.
- 메모리 페이지에 modification이 없으면, parent하고 child process가 같은 공통 페이지를 사용. Modification이 있을 경우 해당 페이지 복사본을 만들어 parent/child가 서로 따로 페이지를 쓰게 함.
- 다만, 이론적으로는 child process가 덤프 내리는 중, 공통 페이지에 대한 modification이 만들어질 수 있기 때문에, Linux에서는 child process가 실제로 얼마나 많은 메모리를 사용할 줄 모름. (얼마나 많은 페이지를 부모와 공통으로 쓸 수 있는지, 그리고 얼마나 많은 페이지의 복사본을 만들어야 하는지)
- Redis가 background에서 저장 명령을 실행 할 때, copy-on-write fork를 사용함.
- overcommit_memory 설정이 0(기본값)으로 되어 있는 경우, free memory가 Redis의 dataset의 2배는 되어야 함. 안 그러면 저장 시, Redis가 죽음.
- overcommit_memory 설정을 1로 하여 Optimistic Memory Allocation을 사용(추천)
- Optimistic Memory Allocation
- 프로그램 A는 자신에게 할당된 메모리 전체를 실제로 사용하고 있지 않다고 가정을 바탕으로 함
- Linux가 실제 물리적 멤모리보다 더 많은 가상메모리를 할당 해줄 수 있음.
- Redis가 자신에게 할당된 물리 메모리를 다 사용하고 있을 경우, malloc 호출 시 null pointer를 돌려받는게 아니라, 가상 메모리 포인터를 받음. 이 가상 메모리 포인터를 사용하면, kernel에서 이 포인터를 실제 메모리에 매핑을 하려고 함.
- 이 때 Out of Memory가 발생 할 경우, kernel에서는 mallloc 호출한 해당 프로세스(Redis)를 죽임. “OOM killer terminated this process” 문구가 뜸..
- Optimistic Memory Allocation
- 가능하다면 가장 최신 stable 버전을 사용 (개인적인 견해)
- Redis의 개발자(antirez, 본명: Salvatore Sanfilippo)는 엄청난 분이시긴 하지만, 심각한 보안/성능 이슈가 자주 있는 편임.
- Redis instance에 암호 설정이 안 되어 있을 경우, Redis 프로세스 사용자의 public key를 마음대로 덮어 씌울수 있는 버그. http://antirez.com/news/96
- Replica에서 expiration이 제대로 안 되었던 이슈. https://engineering.grab.com/a-key-expired-in-redis-you-wont-believe-what-happened-next
- Redis의 개발자(antirez, 본명: Salvatore Sanfilippo)는 엄청난 분이시긴 하지만, 심각한 보안/성능 이슈가 자주 있는 편임.
- Redis 4. 0에서 부터 일부분의 기능에 대해서 조금씩 multithread 활용하기 시작함. 예: background에서 object 삭제
상용에서는…:
- HA(고가용성) ? -> Redis Sentinel
- Scale out ? -> Redis Cluster
- 트래픽이 엄청나게 많다면, CPU affinity 설정 추천
- 네트워크 패킷 처리용 CPU와 Redis process에서 사용할 CPU를 분리해야 함. 같은 CPU를 쓸 경우 성능저하 발생.
- RPS(Receive Packet Steering) 설정을 사용하여, 네트워크 패킷 처리용 CPU를 지정
- taskset을 사용하여 Redis process에 할당 될 CPU 목록 설정
- Ref: https://viblo.asia/p/redis-for-true-high-loads-bWrZnBkpZxw
- 10% 정도 성능 향상
생소하지만 쓸만한 Redis 기능 & 데이터 타입:
- sorted set
- 스코어보드/랭킹테이블 용도로 매우 쓸만함
- 예: 게임 스코어 랭킹에서 1위부터 10위까지 열람
- 예: “홍길동"의 랭킹은?
- 사전순서 sort도 가능
- 스코어보드/랭킹테이블 용도로 매우 쓸만함
> zadd hackers 0 "Alan Kay" 0 "Sophie Wilson" 0 "Richard Stallman" 0 "Anita Borg" 0 "Yukihiro Matsumoto" 0 "Hedy Lamarr" 0 "Claude Shannon" 0 "Linus Torvalds" 0 "Alan Turing"
> zrange hackers 0 -1
1) "Alan Kay"
2) "Alan Turing"
3) "Anita Borg"
4) "Claude Shannon"
5) "Hedy Lamarr"
6) "Linus Torvalds"
7) "Richard Stallman"
8) "Sophie Wilson"
- Pub/sub 기능
- chat room, 실시간 update/broadcasting용으로 매우 유용
- 예: chatroom/온도센서/주식가격 변동
- chat room, 실시간 update/broadcasting용으로 매우 유용
- Bit arrays (or simply bitmaps)
- large domain에 대한 boolean 값을 저장해야 할 때 유용
- metric/통계 용도로 유용
- large domain에 대한 boolean 값을 저장해야 할 때 유용
- Hyperloglog (developed by Philippe Flajolet)
- 적은 메모리로, 엄청 큰 데이터에 대한 Cardinality(집합원 개수)를 계산할 때 매우 유용
- 예: 구글 검색페이지 방문객 unique IP 개수
- 적은 메모리로, 엄청 큰 데이터에 대한 Cardinality(집합원 개수)를 계산할 때 매우 유용
- 일반적으로 cardinality를 구하기 위해서는, cardinality에 비례한 메모리가 필요함
- 예: 구글 검색페이지 포털 방문객의 unique IP 개수를 구하려면, 방문객의 IP set을 들고 있어야 함….
- 예: 구글에서 실행된 unique 검색어 개수를 구하려면, 실행된 검색어에 대한 set을 들고 있어야 함….
- 예: Nugu 누적 발화문 unique set…
- 일반적인 방식으로는, cardinality를 구하는 것은 실용이지 않음
- Hyperloglog를 사용하면 매우 적은 메모리 사용만으로도 cardinality를 구할 수 있음.
- 다만, 작은 error margin이 있음
- error margin은 메모리 사용량에 따라 조절가능
- 예: http://d2.naver.com/helloworld/711301
- “셰익스피어 전 작품에 사용된 총 67,801개의 단어를 정확히 세려면 Java의 HashSet으로는 약 10MB의 메모리가 필요하다. 반면 HyperLogLog를 사용하면 결과는 정확한 값과 3%의 차이가 있지만 HashSet이 필요로 하는 메모리 크기의 1/2,500인 512바이트만 사용하는 것을 확인할 수 있다.”
- Hyperloglog란?
- hash value의 binary 값을 보고 통계적으로 근접한 cardinality를 구함
50% of hashed values will look like this: 1xxxxxxx…x25% of hashed values will look like this: 01xxxxxx…x12.5% of hashed values will look like this: 001xxxxxxxx…x6.25% of hashed values will look like this: 0001xxxxxxxx…x- 예: 8개의 item이 있다면, 한개 정도는 001로 시작할 것을 예상할수 있음
- 예: 001xxxxx…x의 값이 나왔다면, cardinality는 아마도 8임.
- 여러개의 bucket을 사용
- 특정 hash에게 배정된 bucket에 ‘0'의 최대 연속개수를 저장.
- 예: 001 보다 000001이 더 높음. 000001의 연속 ‘0’ 개수는 5.
- Redis Hyperloglog에서는 각 bucket의 ‘0'의 최대 연속개수를 가지고, 평균 cardinality값을 돌려줌
- 예: 2개의 bucket에 유효 값이 있고, 해당 값이 01xxx, 001xxx임. 평균 cardinality는 6 (avg of 4 & 8).
- Redis에서는 1개의 Hyperloglog 데이터에 12KB의 메모리가 사용됨
- 12KB 짜리 Hyperloglog key 1개에서 구할 수 있는 cardinality는 거의 무한대($2^{64}$.. or 9,223,372,036,854,775,807 items)
- Standard error은 0.81%.
- Hyperloglog 사용 사례:
- Fastly (글로벌한 CDN 제공자). https://www.infoq.com/presentations/probabilistic-algorithms
- Google Cloud BigQuery: https://cloud.google.com/blog/big-data/2017/07/counting-uniques-faster-in-bigquery-with-hyperloglog
- Hyperloglog key 데이터가 12KB?
- 16384개의 ‘register’(bucket)을 사용.
- 각 register는 6 bit.
- 16384 * 6 bits -> 12 K(ibi)B
- 왜 6bit?
- item의 hash값(64bit)의 앞 14bit는 어느 bucket에 저장할지 결정 ($2^{14}$ = 16384)
- 나머지 50bit에서 연속 ‘0’ 개수를 6bit안에 저장가능 ($2^6$ = 64)
- item의 hash값(64bit)의 앞 14bit는 어느 bucket에 저장할지 결정 ($2^{14}$ = 16384)
- 16384개의 ‘register’(bucket)을 사용.
> PFADD alphabets A B C D E
> PFCOUNT alphabets
(integer) 5
- 로컬에서 테스트 해 봄:
| Data structure | # of keys | Time to add | Time to count | memory | cardinality | error margin |
|---|---|---|---|---|---|---|
| Hyperloglog | 1 million | 45s | 95.493µs | 12KB | 1009839 | 0.9839% |
| Set | 1 million | 44s | 51.112µs | 56.74M | 1 million | 0% |
| Hyperloglog | 2 million | 85s | 77.731µs | 12KB | 2015119 | 0.7% |
| Set | 2 million | 90s | 45.831µs | 113.48M | 2 million | 0% |
결론
- KEYS 명령어는 가급적 사용하지 말자
- 가능다하면 TTL 꼭 설정
- 가급적 hash 데이터 타입 사용
- Redis는 single-threaded임
- Redis는 async하지 않음
- 유용한 Redis data type